05
08/2023
流批一体化
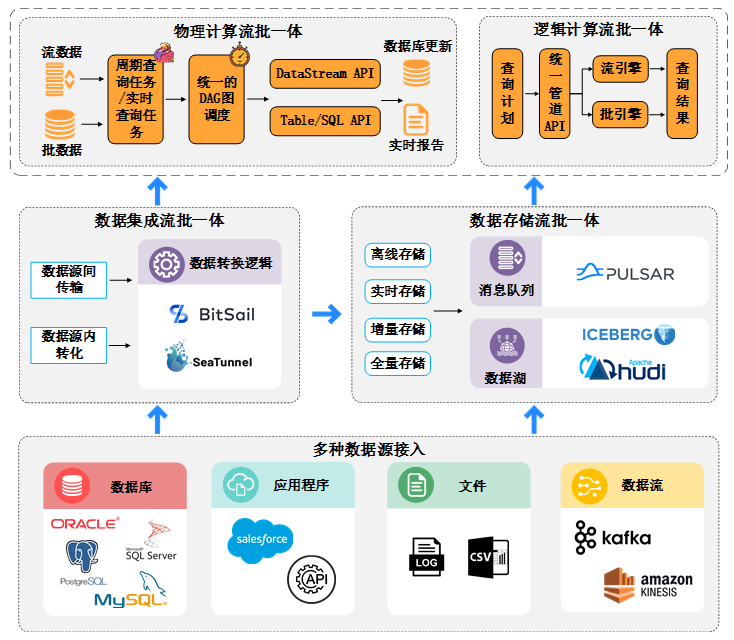
开篇导语流批一体化(Stream-batch Integration)是一项重要的数据处理技术,在多个领域中具有广泛的应用潜力。尽管现有的流处理和批处理方法能够解决各自领域的问题,但是单独使用它们难以满足全面、实时的数据分析需求,同时还会带来开发、运维成本高昂的问题。流批一体化技术通过将实时数据流和批处理数据相结合,不仅能够实现更加全面、准确和实时的数据分析能力,从而为企业提供更加深入的洞察和决策...
22
05/2017
Comparing Hadoop, Spark, and Storm
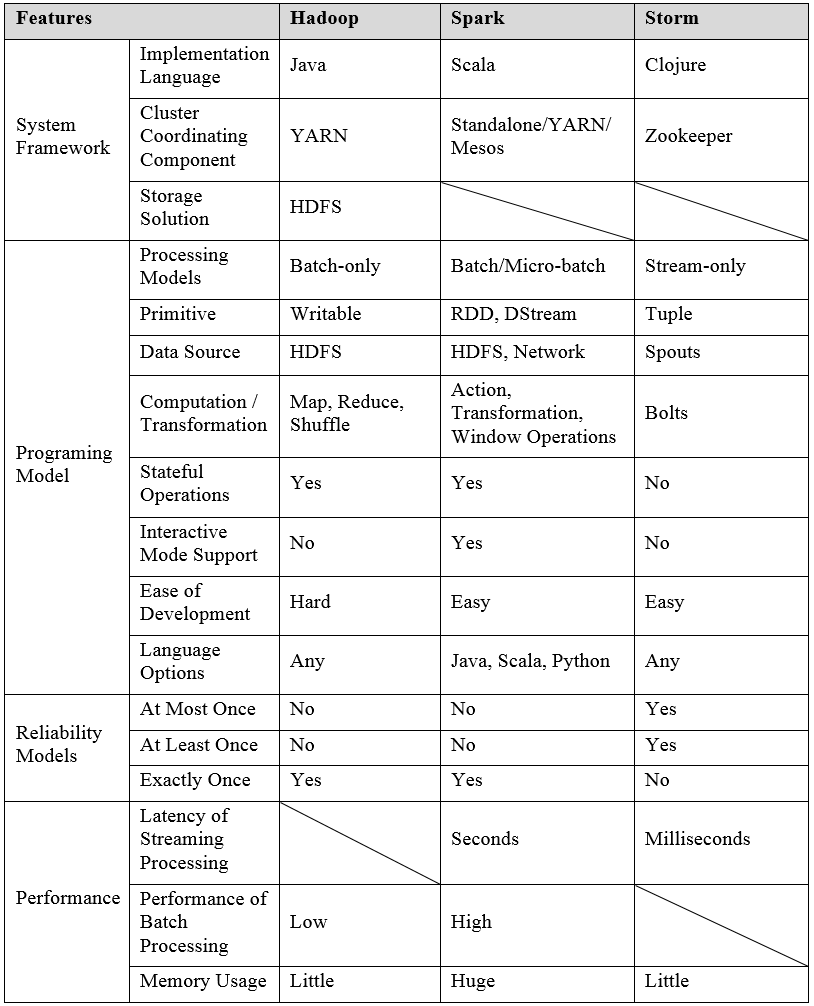
Hadoop, Spark, and Storm have become quite popular in recent times as open-source to work with large sets of data. We will learn about the similarities and differences among these frameworks.Hadoop. H...
27
09/2016
Azure China虚拟机账号转移(2)
此前一篇博客http://www.kangry.net/blog/?type=article&article_id=422说明如何使用Azure Storage Explorer进行Azure虚拟机账号转移。Azure Storage Explorer从2014开始就没有新的版本了,因此其性能有限,功能也不完善。不足之处总结如下:1、拷贝的两个vhd时,必须将源存储账号和目标存储账号最顶的...
23
09/2016
Azure China虚拟机账号转移

由于某些原因,Azure资源需要从一个账户转移到另外一个账户。对于Global Azure来说,这种转移是非常方便的,只需要通过azure support在后台无缝转移即可。对于China Azure,事情就麻烦了(侧目:中国Azure就是个阉割版)。有两种方式转移Azure的资源:1、若是公司的合同Azure,可以通过公司出面,将其资源转入到另一个订阅中。2、若公司无法出面,那么就得手动转移了。...
24
08/2016
Hadoop on Azure (2) - 使用查询控制台或远程桌面运行Hive
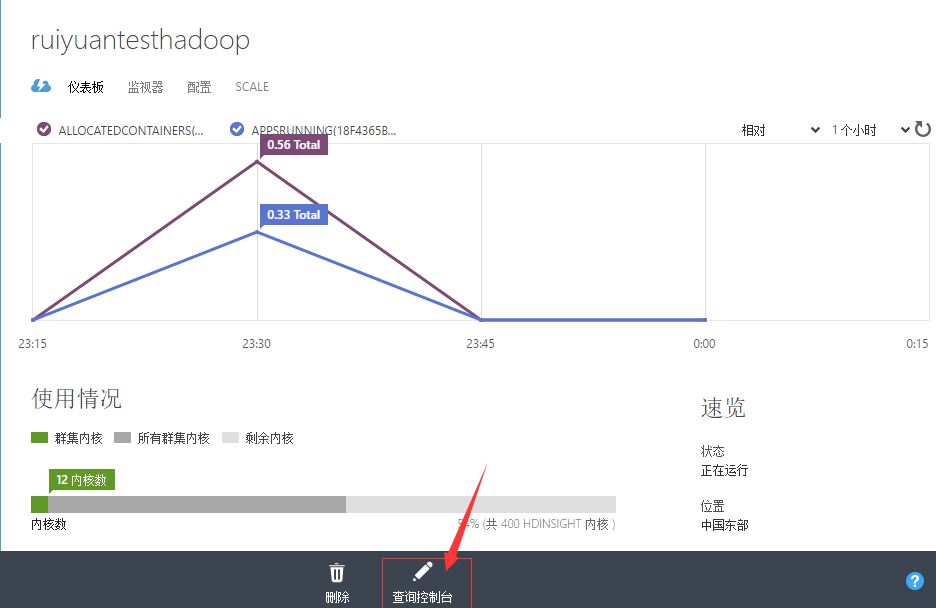
这是Hadoop on Azure的系列文章。此前的文章列表:Hadoop on Azure (1) - Create a Hadoop in HDInsight假设已经按Hadoop on Azure (1) - Create a Hadoop in HDInsight创建好了Hadoop。这篇文章介绍如何使用查询控制台或远程桌面运行Hive。使用查询控制台运行Hive1、通过Azure Por...
23
08/2016
Hadoop on Azure (1) - Create a Hadoop in HDInsight

随着数据爆炸时代的到来,单机的容量以及数据处理速度越来越显得无法适从,因此分布式处理平台因运而生。而Hadoop是这些分布式处理平台的佼佼者,它开源、易于扩展。本文主要介绍在微软Azure云平台上搭建Hadoop系统。1、首先得拥有一个Azure的订阅号。这里我使用Azure China的订阅号。截止到2016年8月,Azure China的新portal无法创建Hadoop,因此我们将使用经典P...
22
08/2016
Spark on Microsoft Azure(3)-Using Jupyter notebook to Predict Building Temperature
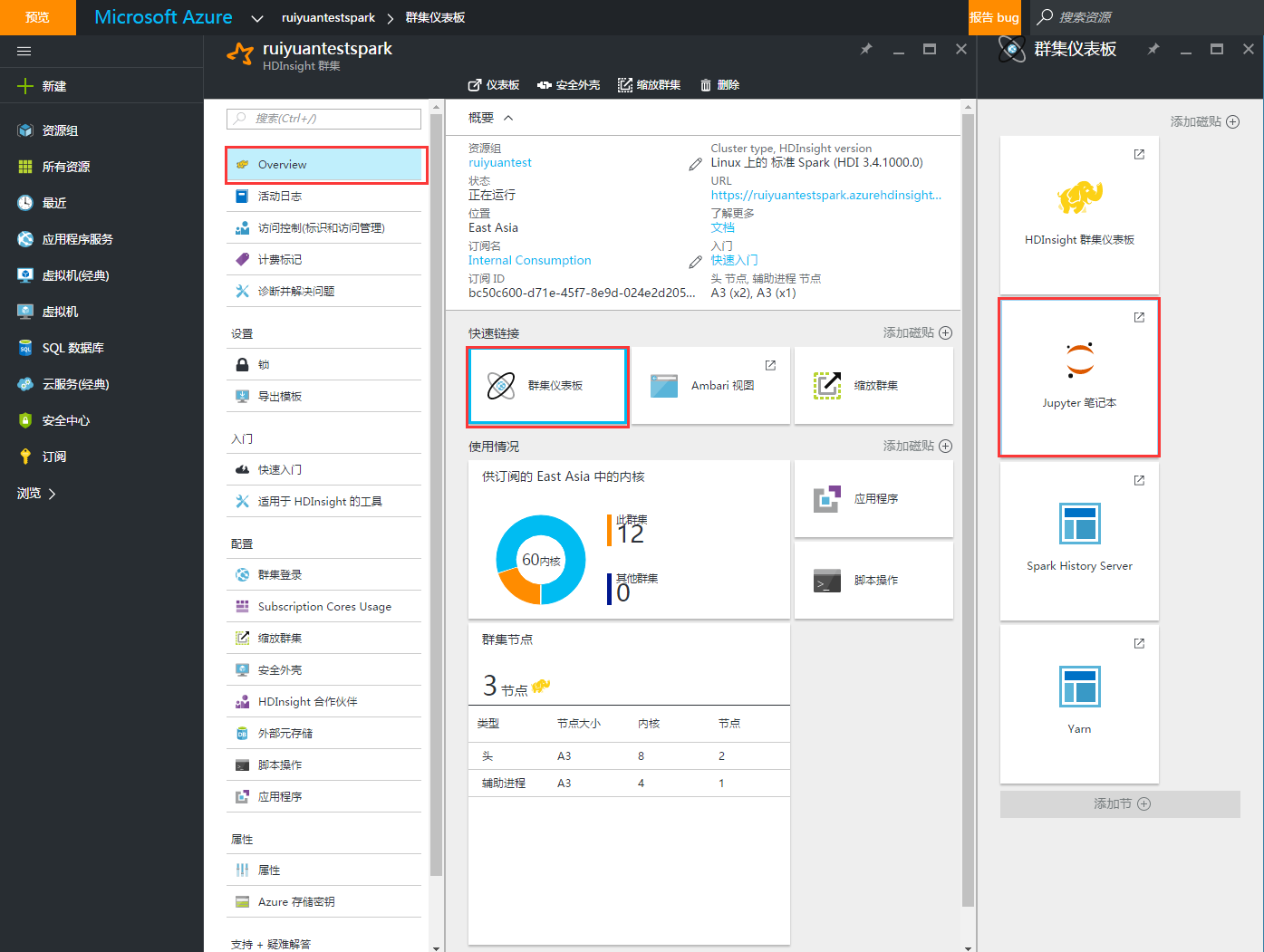
这是Spark in Azure系列文章。Spark on Microsoft Azure(1)-Create a Spark in HDInsightSpark on Microsoft Azure(2)-Using Jupyter notebook to run a spark SQL query此前的文章介绍了如何在Azure中创建Spark集群,以及如何利用Jupyter在Spark中运行...
22
08/2016
Spark on Microsoft Azure(2)-Using Jupyter notebook to run a spark SQL query

这是Spark in Azure系列文章。Spark on Microsoft Azure(1)-Create a Spark in HDInsight此前的文章介绍了如何在Azure Portal中创建Spark。这篇文章主要介绍使用Jupyter笔记本执行sql查询。Azure HDInsight中默认包括了Jupyter笔记本。使用Jupyter笔记本,你可以使用两种不同的内核来执行,PyS...
21
08/2016
Spark on Microsoft Azure(1)-Create a Spark in HDInsight

Spark是一个开源、分布式、基于内存的实时处理平台。与Hadoop相比,由于Spark是基于内存的,减少了磁盘IO,因此具有更好的性能。这篇文章主要讲述Microsoft Azure HDInsight上的Spark平台。1、首先得拥有一个Azure的订阅号。截止到2016年8月,Spark只存在于Azure Global版本中,Azure China并未上线。2、截止到2016年8月,只在Az...
04
05/2016
Azure Table深入理解

> 1、同一个Table中的相同Partition Key是否存在同一个文件中? Azure Table为如下所示的三层结构。Stream层是最终数据存放的位置,Partition层对Stream层的数据进行分区(Partition)管理。在Stream层,数据以Extent为单位进行复制。每个Extent由Block组成,单个Extent和Block的大小均有上限。一个Stream为一组指...