Comparing Hadoop, Spark, and Storm
Hadoop, Spark, and Storm have become quite popular in recent times as open-source to work with large sets of data. We will learn about the similarities and differences among these frameworks.
Hadoop. Hadoop, as an open-source distributed processing framework, is used for storing huge volumes of data and to run distributed analytics processes on various clusters. Hadoop is efficient because it does not require big data applications to transmit large volumes of data across a network. Another advantage of Hadoop is that the big data applications keep running even if the clusters or individual servers fail. As Hadoop MapReduce has a limitation of batch processing one job at a time, Hadoop is mainly used in data warehousing rather than data analytics that need to access data frequently or interact with people instantaneously.
Spark. Spark is a data parallel open-source processing framework, which combines batch, streaming, and interactive analytics in one platform via in-memory capabilities. Spark facilitates ease of use, providing the ability to quickly write applications with built-in operators and APIs, along with faster performance and implementation. It also facilitates robust analytics, with out-of-the-box algorithms and functions for complex analytics, machine learning and interactive queries. Spark also supports variety of languages such as Java, Python and Scala.
Storm. Storm is a task parallel, open-source processing framework for streaming data in real time. Storm has its independent workflows in topologies, i.e. Directed Acyclic Graphs. A topology is composed of Spouts, Bolts, and Streams, where a Spout acts as a data receiver from external sources and creator of Streams for Bolts to support the actual processing. The topologies in Storm work continuously until there is some flaw or the system shuts down. Storm does not run on Hadoop clusters but uses Zookeeper and its own minion worker to manage its processes. Storm can read and write files to HDFS.
Similarities among Hadoop, Spark and Storm. 1) All three are open-source processing frameworks. 2) All these frameworks can be used for Business Intelligence and Big Data Analytics, though Hadoop can only be used for analyzing historical data with no instantaneously responding requirement. 3) Each of these frameworks provides fault tolerance and scalability. 4) Hadoop, Spark, and Storm are implemented in JVM (Java Virtue Machine)-based programming languages: Java, Scala, and Clojure, respectively.
The table below presents the comparison among Hadoop, Spark and Storm:
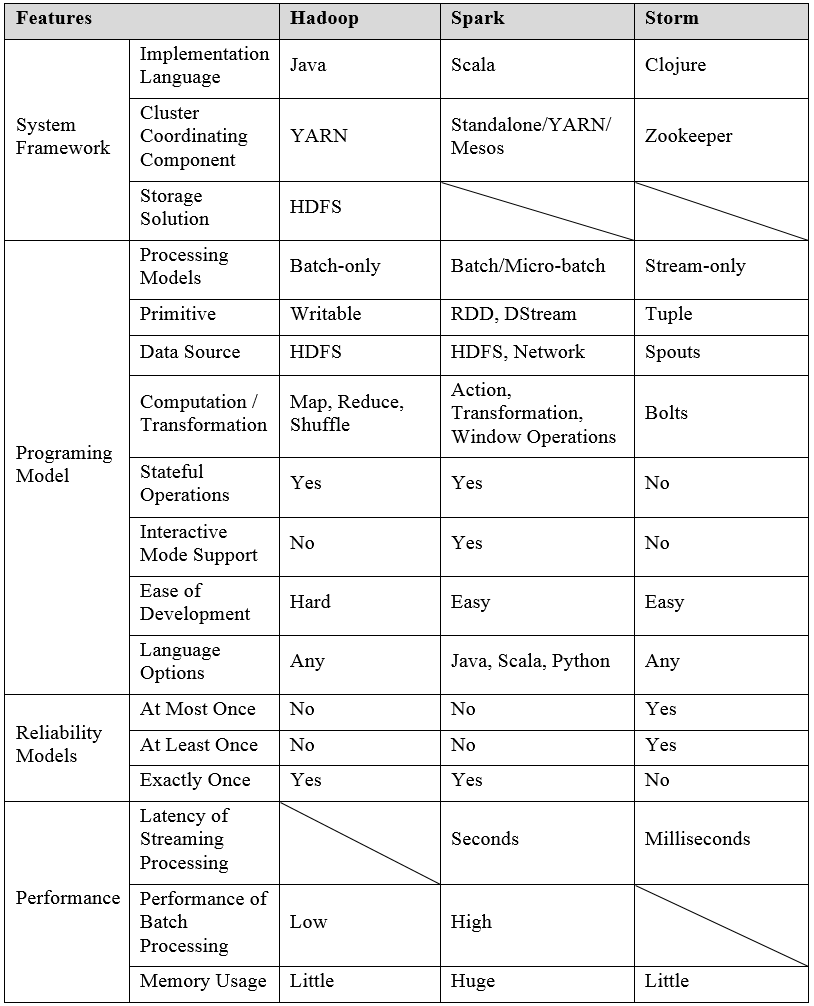
1) Hadoop vs. Spark.
When comparing Hadoop and Spark, people actually mean to compare Spark and Hadoop MapReduce (the processing engine for Hadoop), both of which use HDFS to store data in a reliable and secure manner. The main difference between them are three-fold:
First, Spark processes in-memory data, loading the process in the memory and storing it for caching. Thus, Spark requires large memory. Hadoop MapReduce, on the other hand, limits to the writing data to and reading data from disks after a map or a reduce action. Thus, Spark has a better efficiency than Hadoop MapReduce in analyzing data.
Second, Hadoop MapReduce is designed for batch processing one job at one time. Before a job is finished, Hadoop MapReduce cannot run another job. However, Spark, using its own streaming API rather than YARN for functioning, allows independent processes for continuous batch processing at short time intervals. Thus, Spark can be used for batch processing as well as real time processing.
Third, not limited to data processing, Spark has a diversity of feature for data analytics. For example, it can process graphs by using existing machine learning libraries. It has in-built interactive mode that allows people (or algorithms) to interactively modify parameters of a model based on the results generated by the model with previous parameters. Such feature well supports the philosophy of machine learning, in which parameters are tuned iteratively based on the errors generated in each iteration. The in-built interactive mode can also enable interactive queries, where people can re-specify their query conditions based on the results retrieved by the previous queries. Spark also provides high-level APIs in Java, Scala and Python.
2) Spark vs. Storm.
When comparing Spark and Storm, we focus on the streaming aspects of each solution.
First, Spark Streaming and Storm use different processing models. Spark Streaming uses micro-batches to process events while Storm processes events one by one. As a consequence, Spark Streaming has a latency of seconds, while Storm provides a millisecond of latency. Spark’s approach let us write streaming jobs the same way we write batch jobs, facilitating us to reuse most of the code and business logic. Storm focuses on stream processing (some refer to it as complex event processing), the framework of which uses a fault tolerant approach to complete computations or to pipeline multiple computations on an event as it flows into the system.
Second, Spark Streaming provides a high-level abstraction called a Discretized Stream or DStream, which represents a continuous sequence of RDDs. Storm works by orchestrating DAGs in a framework called topologies, which describes the various transformation or steps that will be taken on each incoming piece of data as it enters the system. The topologies are composed of Streams, Spouts, and Bolts.
Third, Storm offers at-least-once processing guarantees, meaning that it can guarantee that each message is processed at least once, but there may be duplicates in some failure scenarios. It also offers at-most-once processing guarantees, which means that each message is processed at most once. Storm does not guarantee that messages will be processed in order (To achieve exactly-once, stateful, and in-order processing, Storm introduces an abstraction called Trident[30], but it is beyond the scope of this book). Inversely, Spark Streaming yields perfect, exactly once, and in-order message delivery.
Fourth, different from Spark Streaming, which only supports Java, Scala, and Python, Storm has very wide language support, giving users many options for defining topologies.
3) Storm vs. Hadoop.
Basically, Hadoop and Storm frameworks are used for analyzing big data. Both of them complement each other and differ in some aspects.
Firstly, Hadoop is an open source framework for storing and processing big data in a distributed fashion where data is mostly static and stored in persistent storage on large clusters of commodity hardware. Storm is a free and open source distributed real-time computation system, which works on the continuous stream of data instead of stored data in persistent storage.
Secondly, Storm adopts master-slave architecture with Zookeeper-based coordination. The master node is called as nimbus and slaves are supervisors. Hadoop takes master-slave architecture with/without Zookeeper-based coordination. The master node is job tracker, and the slave node is task tracker.
Thirdly, Storm topology does not guarantee the messages will be processed in order, and runs until shutdown by the user or an unexpected unrecoverable failure. On the contrary, MapReduce jobs in Hadoop are executed in a sequential order, and the process is exterminated as soon as the job is done.
0 条评论