Hadoop on Azure (2) - 使用查询控制台或远程桌面运行Hive
这是Hadoop on Azure的系列文章。此前的文章列表:
Hadoop on Azure (1) - Create a Hadoop in HDInsight
假设已经按Hadoop on Azure (1) - Create a Hadoop in HDInsight创建好了Hadoop。这篇文章介绍如何使用查询控制台或远程桌面运行Hive。
使用查询控制台运行Hive
1、通过Azure Portal,进入创建的Hadoop,点击下方的查询控制台按钮,如下所示。
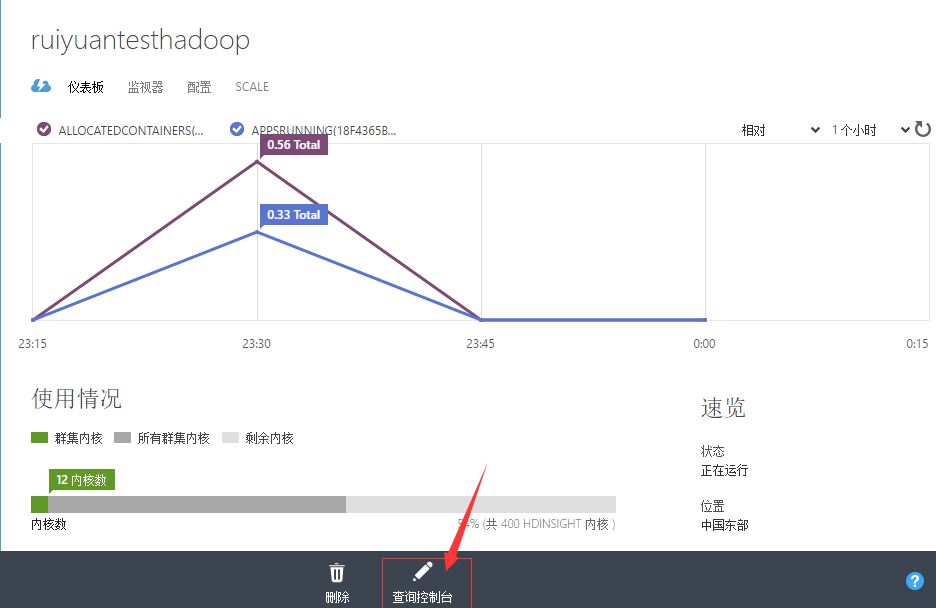
2、进入Hadoop查询控制台,点击导航栏中的Hive Editor,然后在文本框中输入以下代码(稍后我们会对代码作解释),然后点击Submit按钮。若执行完毕,下方的Job Session表格的Status将会显示为Completed,然后点击View Details。
set hive.execution.engine=tez; DROP TABLE log4jLogs; CREATE EXTERNAL TABLE log4jLogs (t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION 'wasbs:///example/data/'; SELECT t4 AS sev, COUNT(*) AS count FROM log4jLogs WHERE t4 = '[ERROR]' AND INPUT__FILE__NAME LIKE '%.log' GROUP BY t4;

3、在新弹出的页面中,我们将会看到作业执行结果,如下图所示。该页面展示了查询代码、作业输出、作业日志等信息。
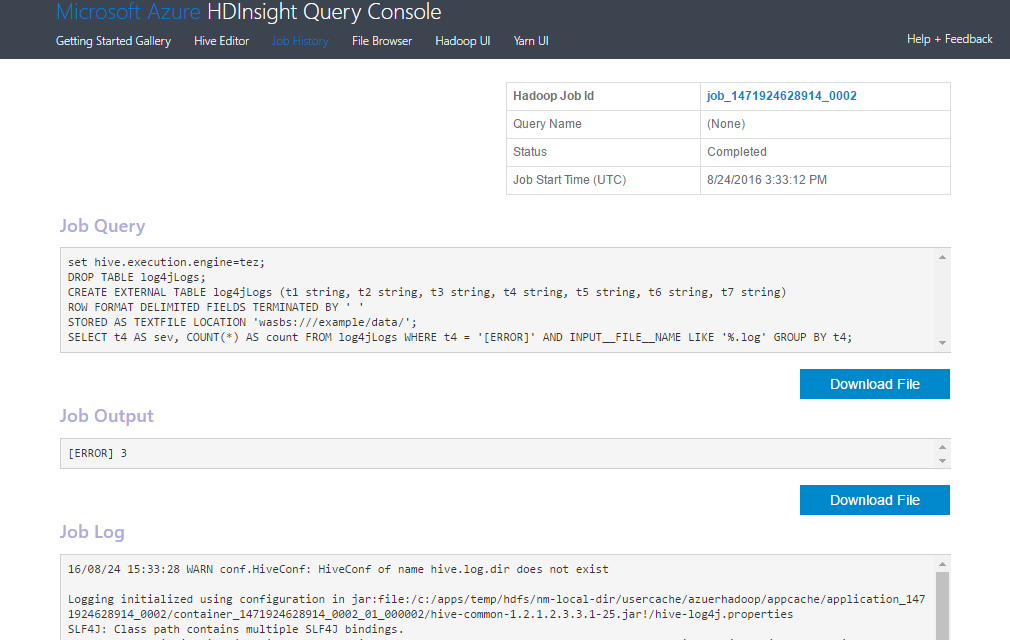
4、下面我们介绍一下第2步的代码。
(1)代码第1行,set hive.execution.engine=tez; 表示使用tez引擎。默认情况下,HDInsight的Hive使用MapReduce引擎而非tez引擎。tez引擎的性能更好。Apache Tez是可让数据密集型应用程序(例如 Hive)大规模高效运行的框架。
(2)DROP TABLE log4jLogs;表示若存在log4jLogs表,则删除它。
(3)3-6行的代码表示使用example/data/下的所有文件创建一个外部表log4jLogs,表具有7个不同的字段。我们可以使用Hadoop的控制台查看此文件夹,如下图所示。该文件夹下包含一个文件夹和一个目录。
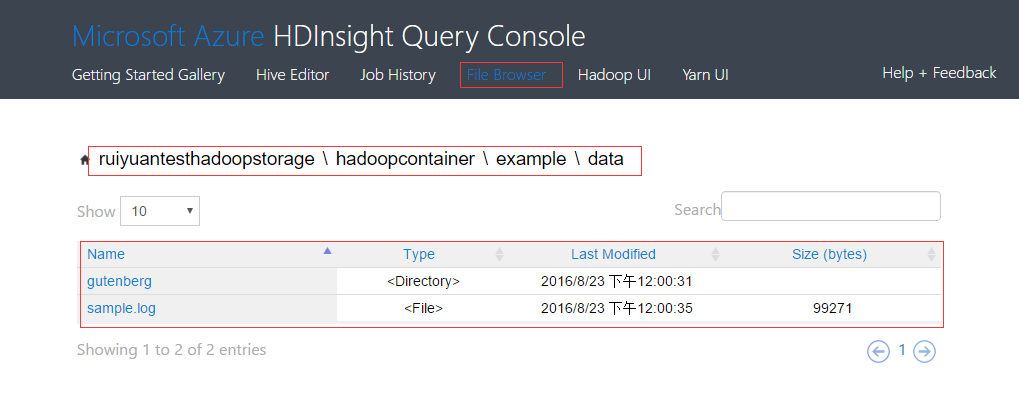
点击sample.log文件即可下载,查看其内容如下。
2012-02-03 18:35:34 SampleClass6 [INFO] everything normal for id 577725851 2012-02-03 18:35:34 SampleClass4 [FATAL] system problem at id 1991281254 2012-02-03 18:35:34 SampleClass3 [DEBUG] detail for id 1304807656 2012-02-03 18:35:34 SampleClass3 [WARN] missing id 423340895 2012-02-03 18:35:34 SampleClass5 [TRACE] verbose detail for id 2082654978 2012-02-03 18:35:34 SampleClass0 [ERROR] incorrect id 1886438513 2012-02-03 18:35:34 SampleClass9 [TRACE] verbose detail for id 438634209 2012-02-03 18:35:34 SampleClass8 [DEBUG] detail for id 2074121310 2012-02-03 18:35:34 SampleClass0 [TRACE] verbose detail for id 1505582508 2012-02-03 18:35:34 SampleClass0 [TRACE] verbose detail for id 1903854437
对于Hive而言,内部表和外部表的区别如下:
外部表:在创建过程中使用关键字EXTERNAL,在导入数据到外部表,数据并没有移动到自己的数据仓库目录下,也就是说外部表中的数据并不是由Hive自己来管理的。当你预期以外部源更新基础数据(例如自动化数据上载过程),或以其他 MapReduce 操作更新基础数据,但希望 Hive 查询始终使用最新数据时,必须使用外部表。删除外部表仅仅删除外部表的元数据,不会删除数据文件。
内部表:创建过程中无需使用EXTENRNAL,在导出数据到内部表时,会将数据移动到Hive的数据仓库目录下(如HDInsight会将数据导入到hive/warehouse/目录下),删除内部表时同时也会删除数据文件。
(4)第6行类似于SQL语句,选择其列t4包含值 [ERROR] 的所有行计数,INPUT__FILE__NAME LIKE '%.log'告诉 Hive,我们只应返回以 .log 结尾的文件中的数据,即sample.log文件。
使用远程桌面运行Hive
远程访问集群的要求为:
基于 Windows 的 HDInsight(HDInsight 上的 Hadoop)群集
运行 Windows 10、Window 8 或 Windows 7 的客户端计算机
1、若在创建时允许了远程访问集群,则直接跳入第3步。
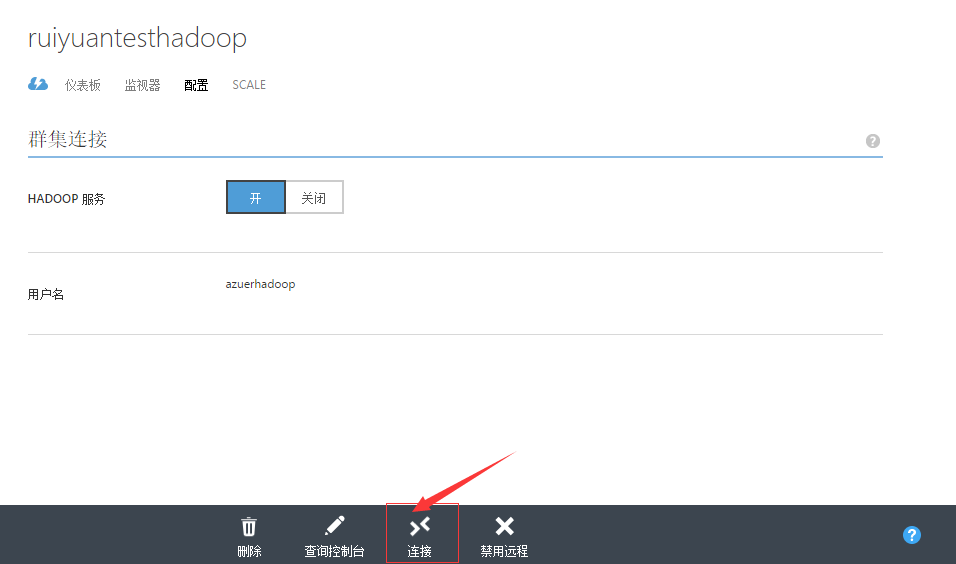
2、若在创建时未允许远程访问集群,则在Portal中进入集群的配置页面,点击下方的“启用远程”按钮。
3、开启了远程的Portal显示如下。点击连接,将会下载一个rdp客户端,双击打开,输入远程连接用户名和密码即可进入。
4、进入远程连接桌面如下图所示。桌面上有三个快捷方式。点击Hadoop Command Line图标
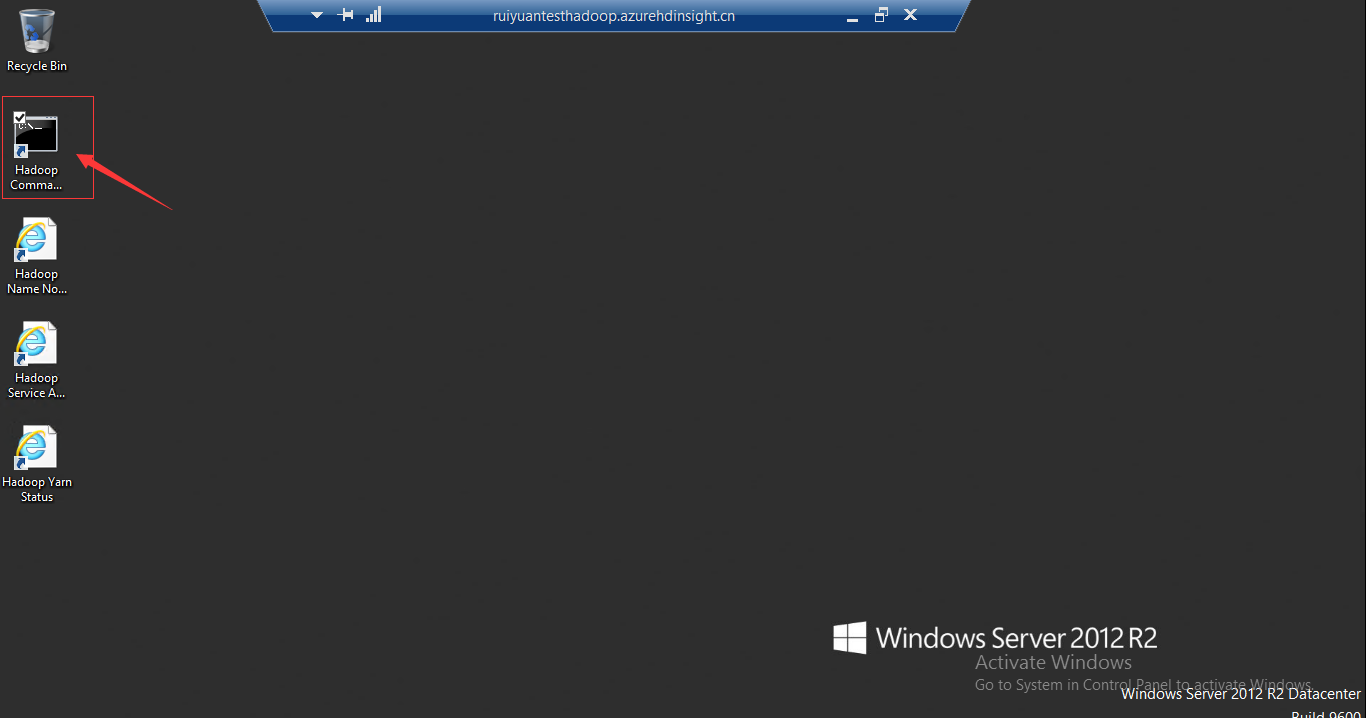
5、在弹出的框中,输入以下命令,进入hive
%hive_home%\bin\hive
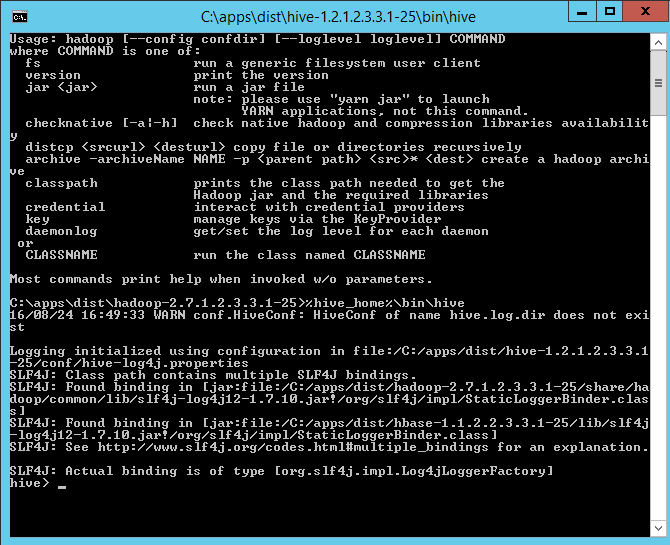
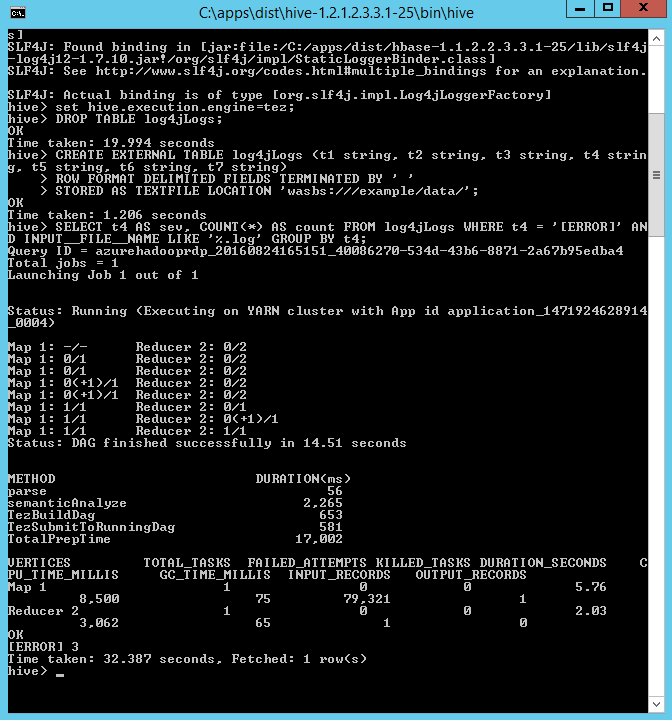
6、依次输入以下命令。
set hive.execution.engine=tez; DROP TABLE log4jLogs; CREATE EXTERNAL TABLE log4jLogs (t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION 'wasbs:///example/data/'; SELECT t4 AS sev, COUNT(*) AS count FROM log4jLogs WHERE t4 = '[ERROR]' AND INPUT__FILE__NAME LIKE '%.log' GROUP BY t4;
输出的结果如下:
0 条评论