郑宇教授最新力作,构建多模态跨领域知识融合新范式(附论文)
人工智能的普及已经促成了各种各样的应用,这些应用弥合了数字世界和物理世界之间的差距。由于物理环境过于复杂,无法通过单一的信息采集方法进行建模,因此融合来自不同来源(如传感器、设备、系统和人员)的多模态数据来解决现实世界中的问题至关重要。但为每个问题部署新的资源,并从头开始收集原始数据既不适用也不可持续。因此,当问题领域的数据不足时,融合来自其他领域已有的多模态数据中的知识至关重要。现有的研究侧重于在单一领域中融合多模态数据,并假设来自不同数据集的知识本质上是对齐的;然而这种假设在跨领域知识融合的场景中可能不成立。本次为大家带来郑宇教授近期发表在SCI期刊TIST的文章《Fusing Cross-Domain Knowledge from Multimodal Data to Solve Problems in the Physical World》。

一. 背景与动机
AI与传感器技术的进步促进数字-物理世界的交互,城市计算、环境监测等领域需多模态数据以捕捉复杂现象。单一数据源往往无法完整刻画复杂的自然和社会现象,在许多任务中,融合多模态数据比使用单一数据集能获得更好的性能。近年来,大模型(如大语言模型、具身智能)进一步推动了多模态融合的发展,比如图文生成、视频理解等。
但目前大多数研究关注单一领域的多模态数据融合(如同一网页上的文字、图片、视频;同一机器人上的多种传感器)。这些数据天然对齐,知识在采集时就已一致。
现实问题往往需要跨域融合,因为目标领域数据不足时,需要借助其他领域已有的数据(例如空气质量预测需要结合交通、气象、城市规划等领域数据)。但这些数据并非为同一目的采集,知识不自然对齐。
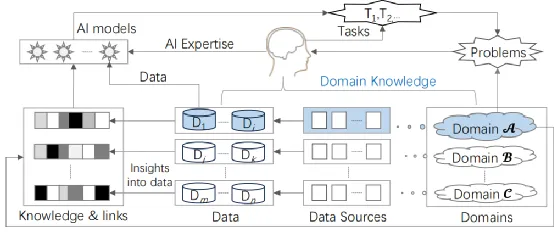
图1. 跨领域知识融合图示
多模态融合有三种应用场景,分别是1)融合了从数字世界获得的多模态数据,其任务旨在解决同样在数字世界中的问题(比如基于文本生成视频);2)融合了来自数字和物理世界的多模态数据,用于解决数字世界中的问题(比如Kinect体感游戏);3)融合了来自两个世界的多模态数据,该任务在数字世界中运行,但旨在解决物理世界中的问题(比如结合天气状况、交通数据和社交媒体来调整城市中心区的交通管制政策)。大多数研究集中在第一种情景,少数研究正步入第二种情景。最后一种情景比较罕见,但对于解决物理世界问题具有重要意义,这也是本文的主要目标,尽管论文的框架适用于所有这三种情景。
并且跨领域知识融合至少会带来两个主要收益。一是极大地减少了数据收集的工作量,因为物理世界非常复杂,一个领域的数据经常不足以解决特定的问题。为每一个人工智能任务部署新的资源既不可行也不可持续。二是能提高解决问题的能力,实现更准确的预测、更早的异常检测和更可靠的分布估计。
但单领域与多领域、虚拟世界与物理世界的差异给数据融合带来了新的挑战,包括来自不同领域、不同数据的知识对齐,融合过程中需处理每个数据集中的数据不足问题以及数据异构问题。因此在将数据放入模型的结构之前,论文回答了What、Why、How三个问题,即融合什么、为什么能融合以及怎么融合。
论文提出一个了四层框架(Domains、Links、Models、Data)来回答上述三大问题。Domains层回答“What”问题,Links层回答“Why”问题,Models层回答“How”问题,而Data层所提出的数据转换模块将不同结构、分辨率、尺度和分布的数据转换为一致的表示,以便输入到人工智能模型中。
为了方便您后续的阅读和理解,给出表1和图2来解释一些概念。
表1. 文中概念及其定义
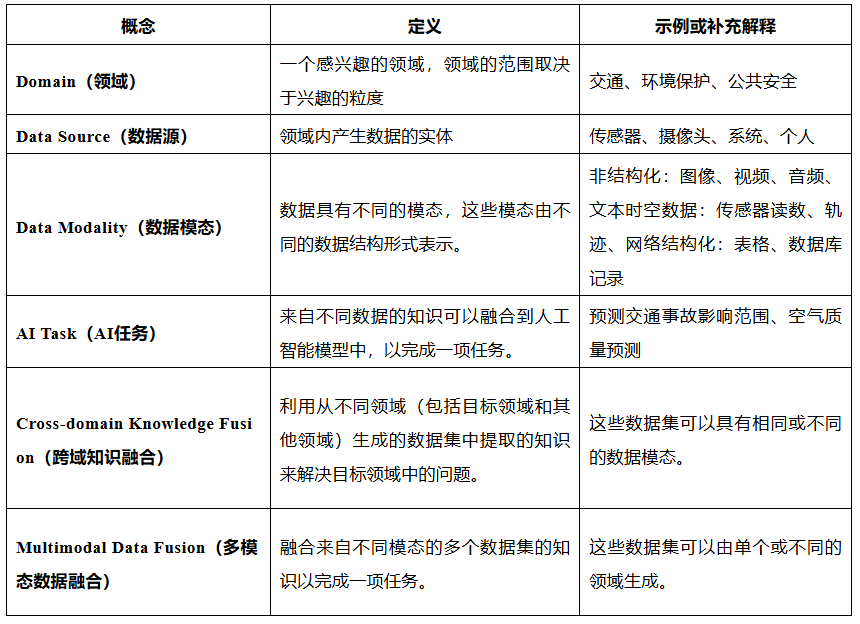
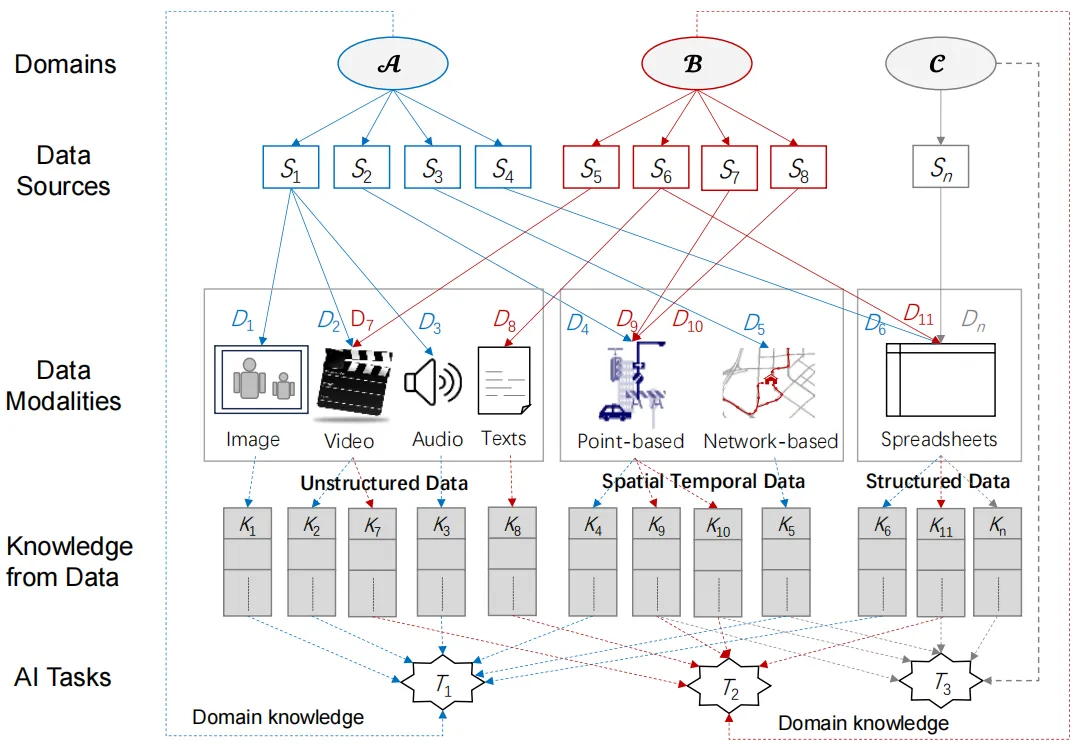
图2.跨域多模态数据融合关键概念图解
二. 方法介绍
2.1 跨领域知识融合的通用框架
图3展示了跨领域知识融合的方法框架,它由四个层组成:领域层、链接层、模型层和数据层。
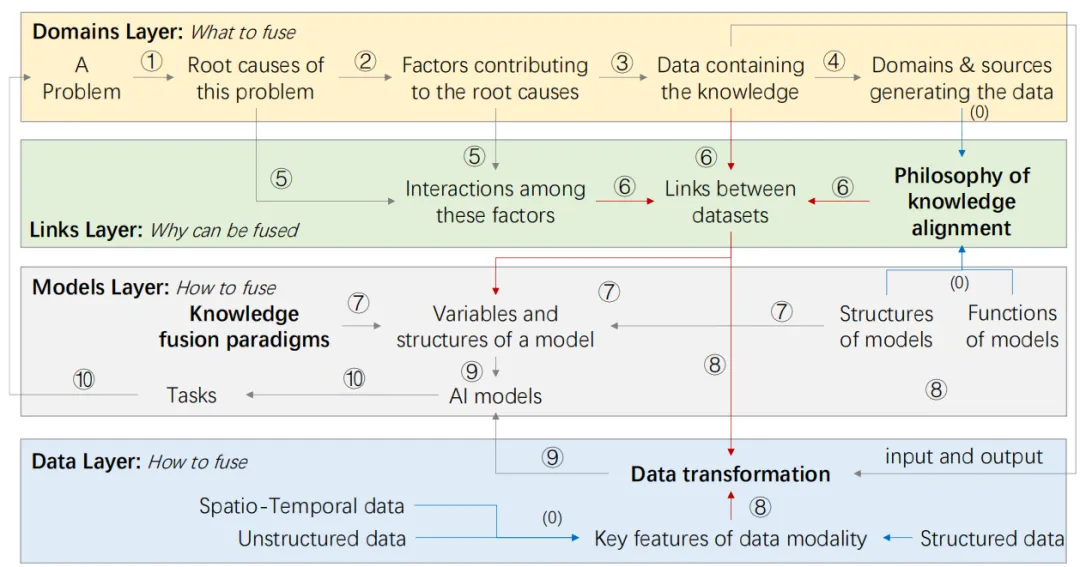
图3. 跨领域多模态数据融合的方法框架
2.1.1步骤
在领域层:
①基于相关领域知识分析问题的根本原因。
②挖掘导致根本原因的主要因素。
③探索包含这些因素知识的相关数据。
④搜索生成这些数据集的数据源和领域。
在链接层中:
⑤识别因果因素之间的相互作用。这一步基于领域知识构想因果因素之间的粗略交互,因为很难获得精确的交互。
⑥基于三个输入设计数据之间的链接:三个输入即因果因素之间的相互作用、数据包含的知识以及知识对齐的方法。知识对齐方法是推导数据融合模型的基础,包括基于多视图、基于相似度、基于依赖和基于共性的知识对齐原则(后续2.2节会介绍)。
在模型与数据层中:
⑦基于所选数据、知识融合的范式和AI专业知识之间的联系,设计具有特定结构和一组变量的AI模型。知识融合有两种范式,由精确融合和粗略融合组成。
⑧根据数据之间的联系和不同数据模态的关键属性,设计选定数据的数据转换算法。不同的数据模态应该有不同的转换算法。同时,同一模态的数据在不同的应用场景下可以有不同的数据转换算法。
⑨结构、变量和数据转换算法耦合在一起,构建最终的AI模型。有时,数据转换算法,例如深度编码器,会是模型结构的一部分。AI模型使用机器学习算法根据选定的数据进行训练。
⑩应用设计的AI模型到定义的任务中以解决问题。
2.1.2数据选择的例子
由于前四个步骤是应用驱动且领域相关的,我们用图4所示的运行示例进行了详细说明,该示例根据现有站点的空气质量读数推断出整个城市的实时和细粒度空气质量。
①分析根本原因:位置A的空气污染主要由三个方面引起:位置A及其周围地方的污染排放、位置A及其周围地方的扩散条件以及位置A不同空气污染物之间的二次化学反应。
②挖掘主要因素:交通条件是导致交通排放的关键因素,交通排放是空气污染的重要来源。 土地利用情况(如建筑物的密度和高度)以及某个地点的气象条件会影响该地点的空气污染的扩散条件。气象也是空气污染物之间二次化学反应的一个因素。
③探索相关数据:兴趣点(POI)和路网数据包含关于一个地点的土地利用和交通状况的知识。在一个地点行驶的车辆的GPS轨迹包含关于该地点交通状况的知识。一个地点的风速、湿度和天气表示其气象条件。
④搜索数据源:我们可以从出租车调度公司获得出租车的GPS轨迹,这是道路交通流量的一部分。 POI和网络数据可以从交通领域的地图服务提供商处获得。气象数据可以通过气象局部署的信息系统从各种传感器中收集。
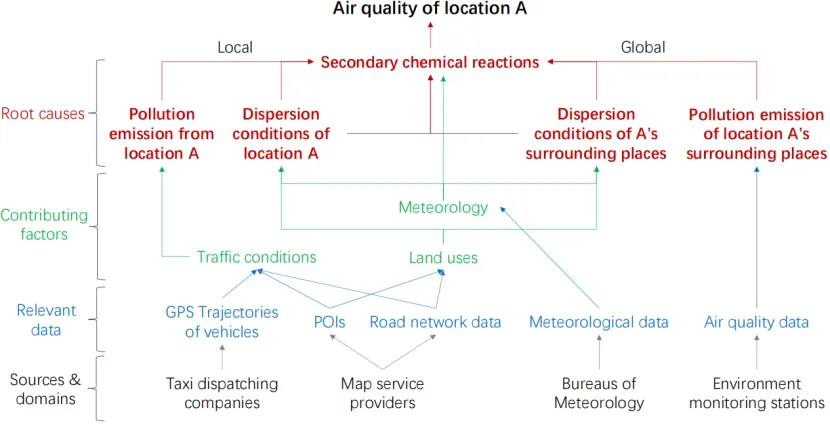
图4. 给定问题选择相关数据的示例
2.2 知识对齐的方法(Links层)
Links层通过提出的四个知识对齐原则来回答了为什么能跨域数据融合的问题。它们揭示了来自不同数据的知识之间的互补性质,而与人工智能模型的结构无关。如图5所示,它们支持跨领域知识融合模型的设计。每个原则都可以促进各种人工智能模型结构的发展,包括基于深度学习的模型,如卷积神经网络(CNN)、长短期记忆网络(LSTM)、图卷积网络(GCN)和生成式预训练Transformer(GPT),以及非深度学习模型,如耦合矩阵分解、协同训练和概率图模型。
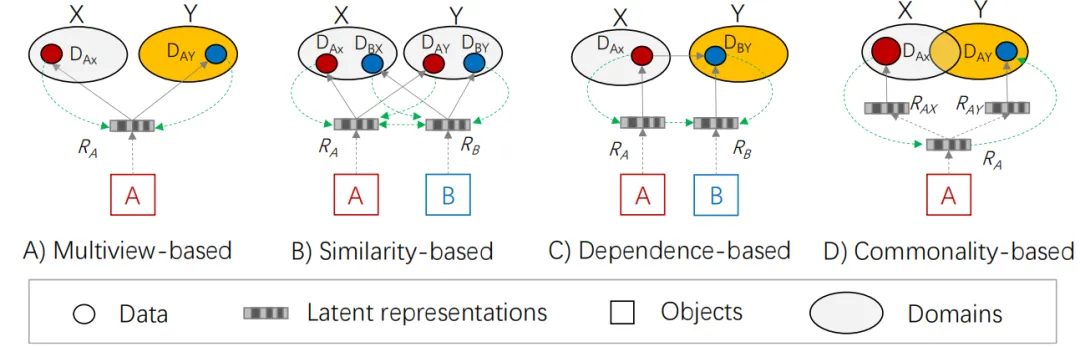
图5. 知识对齐的四个原则
图5中有四个标签,分别表示数据、潜在表示、对象和域。在此,我们仅使用两个对象和两个域进行简单说明。在知识对齐的理念中,数字可以大于2。
2.2.1 基于多视角的原则
该原则旨在寻找不同领域中对同一对象的不同视角,从而更好地理解该对象。
如图5 A) 所示,对象A包含由潜在表示 RA的知识,这些知识无法直接观察到。我们可以获得的是对象A在域X和Y中生成的数据DAX和 DAY。或者,我们可以说 X和Y是观察对象A的两个不同视角。DAX和DAY可以被视为观察记录,共同推导出比仅基于其中任何一个更好的 RA表示。X 和 Y 越不同,关于对象 A 的冗余信息就越少,因此 RA的表示就越好。然后,我们可以基于RA解决问题。
更具体地说,如图6 A)所示,LX和LY分别是DAX和DAY贡献的潜在表示。它们是RA的一部分,共同构成了关于对象A的知识。如果两个视图是不同的,LX和LY是不相交的。
因此,它们共同贡献的知识(LXY = LX∪LY)被最大化,即LXY = LX +LY,如图6 D)最左侧的情况所示。如果两个视图有一些共同之处,则LXY = LX +LY −overlap,如图6 B)所示。两个视图之间的重叠贡献了关于对象A的冗余知识,这些知识可以从DAX或DAY中推导出来。在图6 C)所示的极端情况下,如果两个视图完全重叠或一个视图属于另一个视图,那么它们对RA的贡献最小。
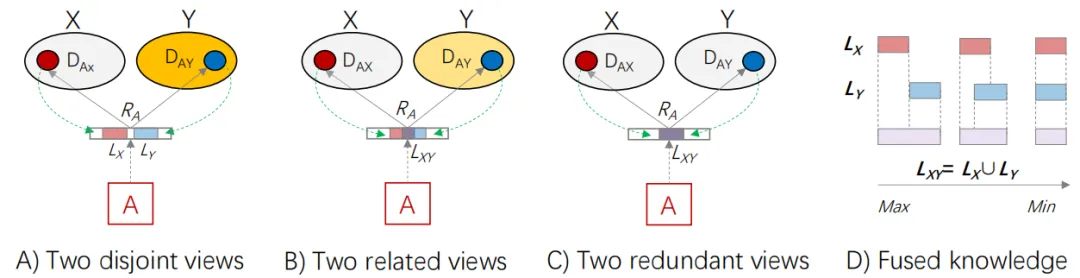
图6. 知识融合的性能取决于视角的区分
2.2.2基于相似性的原则
此原则利用同一类别对象之间的相似性,然后集成来自不同领域的数据,以补充彼此之间的知识。
如图5 B) 所示,从一个单领域场景开始,其中两个对象(A 和 B)在领域 X中生成了数据。在许多情况下,DAX和DBX会非常稀疏,因此难以形成对RA和RB的准确表示。由于对象A和B属于同一类别,它们之间的相似性是有意义的,因此可以用来互补彼此之间的RA和RB。更具体地说,来自 DAX的知识可以通过对象A和B之间的相似性来补充RB,反之亦然。
将场景扩展到两个(甚至更多)领域。在许多情况下,来自单个领域的数据非常稀疏,因此,两个对象之间估计的相似性通常不准确,从而降低了彼此之间互补知识的能力。现在,在领域Y中,分别有对象A和B生成的DAY和DBY。将 (DAX, DBX ) 与 (DAY, DBY) 结合使用,将增强在领域A中解决问题的能力,原因有二。首先,DAY和DBY分别为学习更好的RA和RB提供了互补的观察结果。其次,这种组合提高了估计A和B之间相似性的准确性。DAY和DBY越密集,它们传递给RA和RB的知识就越丰富,估计的相似性就越准确。然而,DAX和DAY 不能简单地链接起来,因为它们具有不同的语义、表示和分辨率;DBX和DBY 也是如此。因此,在复杂的模型中聚合之前,应将它们放置在不同的子模型中,例如矩阵或编码器。
2.2.3基于依赖性的原则
此原则利用不同对象属性之间的依赖关系来加强彼此之间的知识。
如图5 C) 所示,A 和 B 是两个不同类别的对象,它们之间没有有意义的相似性。然而,数据DAX和DBY 分别在域X和Y中生成,它们可能具有概率依赖性,揭示了RA和RB之间的相互作用。这种依赖性为更准确地估计RA和RB提供了上下文和约束,从而提高了任务完成的性能。两个对象之间的依赖性越强,一个对象可以补充给另一个对象的知识就越丰富。
2.2.4 基于共性的原则
此原则利用了不同领域之间的共性,利用对象在一个领域中产生的数据来丰富该对象在其他领域中创建的数据的知识。
如图5 D) 所示,对象A的潜在表示RA生成两个更细粒度的表示RAX和RAY,分别表示A在领域X和Y中的知识。DAX和DAY 是RAX和RAY的观测结果。由于领域X和 Y存在一些共同之处,RAX和RAY将共享一些从RA导出的共同知识。特别地,当DAX丰富而 DAY 稀疏时,我们可以利用从DAX 中学习到的RAX来巩固RA,从而增强生成RAY的能力,这将进一步提高生成DAY的准确性。也就是说,他们的知识可以通过共同构建更好的RA来相互补充。两个领域共享的共性越多,两个领域之间可以转移的知识就越丰富。
更具体地说,如图7 A)所示,LXY = LX ⋂LY表示域X和Y共有的共同点。LX 是RAX的一部分,来源于LXY 。同样,LY是RAY的一部分,也来源于LXY 。域X和Y共享越多,知识LXY 包含的就越丰富,这由紫色块的较大尺寸表示。相反,域X和Y共享越少,LXY 就越小,如图7 C)所示。由于LXY是链接LX和LY的桥梁,更大的LXY可以为从DAX到DAY的知识转移提供更宽的带宽。
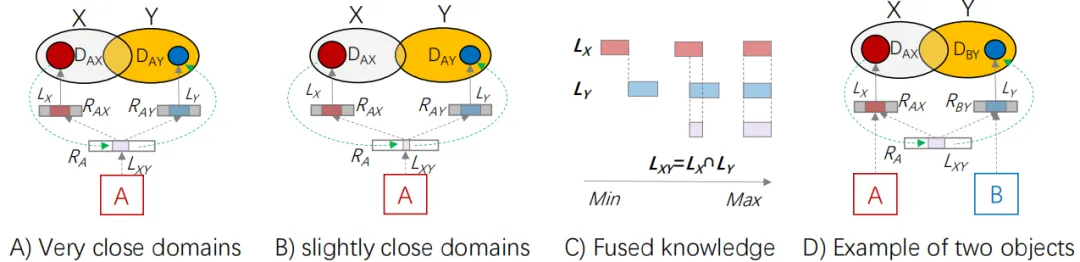
图7. 知识融合的性能取决于领域之间的共性
这四条原则并非互斥,实际工程中经常组合使用,并且四原则为融合提供理论依据,确保科学性和可解释性,避免盲目堆叠数据。
2.3 知识融合范式(Models层)
在确定多模态数据之间的链接之后,可以开始基于两种知识融合范式设计特定的AI模型,这两种范式包括精确融合和粗略融合。
2.3.1两种范式之间的定义和差异
精确知识融合范式首先通过精确的数据转换方法,如地图匹配、图像分割和实体提取,尽可能准确地从每条数据中提取精确知识。然后,这些精确知识基于先前确定的数据之间的联系,在一些可解释的AI模型(如知识图谱、协同过滤和概率图模型)中被显式地链接起来。
粗略知识融合范式首先生成多模态数据的中间表示,这些表示可以被视为粗略的和初步的知识,它使用一些粗略的数据转换方法,例如文本嵌入和图像编码器。然后,基于数据之间的链接,将知识的粗略表示隐式链接起来,这步很可能是在深度学习模型中。
区别:两种知识融合范式的区别在于两个方面。一是第一步中的精确知识与粗略知识的对比。二是第二步中的显式链接与隐式链接的对比。
当满足以下三个要求时,应采用精确融合范式:1) 我们对问题有相对清晰的理解;2) 数据不足;3) 提取的初步知识足够准确。相反,如果对问题的理解模糊,数据丰富,并且初步知识的提取难以准确,则应考虑粗略知识融合范式。
关联性:两种知识融合范式可以结合起来完成复杂的任务。例如,结合知识图谱和大型语言模型来回答复杂的问题,比如“有多少年龄在20到30岁之间的人参观过市中心的艺术博物馆”,或者“有多少老年人独自居住在A社区”。特别地,随着能够自动构建准确和大规模知识图谱的先进方法的出现,我们更有可能利用这两种融合范式来解决一个问题。
2.3.2精确知识融合范式
关于图8中呈现的示例,首先通过精确的数据转换方法从三个数据集中提取关于人和位置的精确知识,这些方法将在后续介绍。例如,我们可以通过将个人在第一个数据源中填写的地址与POI数据库中的地址进行匹配,来建立个人和位置之间的链接。如果匹配成功,则会在个人和特定的POI之间建立链接。与此同时,我们通常会从个人的轨迹中检测停留点,然后根据这些停留点的GPS坐标将其与POI数据库进行匹配。通常,选择距离停留点最近的POI作为个人停留的确切位置。然后,在个人和POI之间创建链接。此外,我们需要从个人的推文中提取POI实体的名称,或者根据个人发布的照片识别特定的POI。
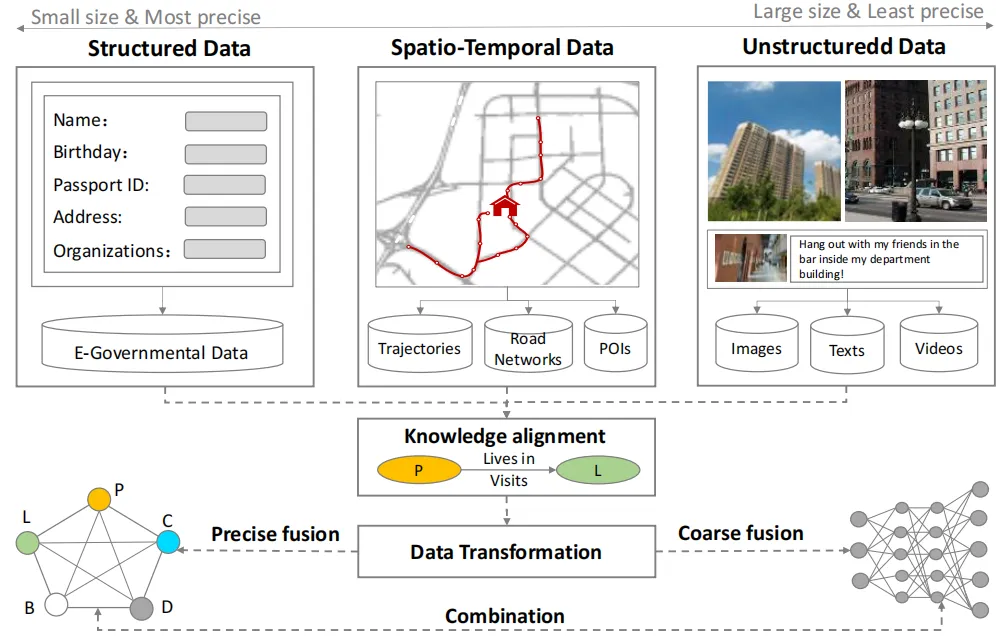
图8. 两种知识融合范式示例
然后,我们可以构建人物和地点之间的显式知识图谱,其中链接可以表示“居住于”、“访问”或“工作于”等,如图8左下方部分所示。同样,个人和组织之间的链接可以被显式构建,然后添加到知识图谱中,其中链接可以表示“为...工作”或“管理”等。之后,我们可以使用为异构信息网络提出的分类算法来标记每个链接的类别,甚至可以使用链接预测算法发现不同节点之间的潜在链接。
例如,如图9所示,我们可以显式地表示用户和位置之间的链接,用矩阵Mx表示,其中每个条目epl表示用户p和位置l之间的链接强度。epl的值可以通过上述方法从三类数据集中精确获得。Mx本质上是稀疏的,因为人们不会访问很多地方。此外,这些数据集只是人们真实生活的一个小样本。
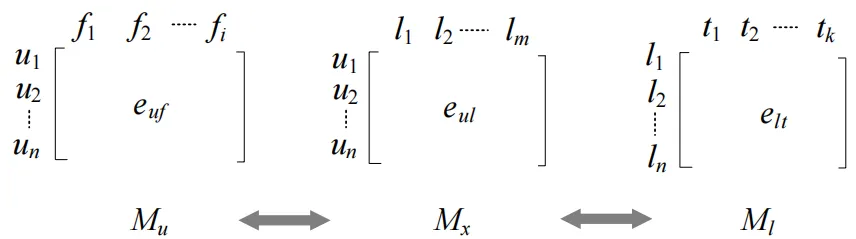
图9. 精确知识融合范式示例
因此,我们可以将结构化数据集中每个用户的个人资料存入矩阵Mu,其中每个条目euf表示用户u’s在个人资料字段f中的特征。同时,我们可以从非结构化数据集中构建矩阵Ml,其中条目elt表示用户在l位置上生成的标签t的存在。
2.3.3粗略知识融合范式
正如我们在图8中看到的,最左边的数据集,即结构化数据,每条数据的大小最小,同时包含最精确的知识。最右边的数据集,即非结构化数据,每条数据的大小最大,但包含的精确知识最少。这就需要复杂的提取和识别算法,而这些算法确实很难做到精确。因此,提出了粗略知识融合范式,首先使用不同类型的编码器或嵌入算法将多模态数据转换为中间表示。
按照图8所示的例子,图10进一步展示了一个粗粒度知识融合范例,其中设计了四个不同的编码器(用四种不同的颜色表示),分别生成个人图像、文本、轨迹和电子表格数据的中间表示。然后,通过一些隐藏层聚合这四个数据集的中间表示,生成关于个人行为和兴趣的潜在表示。经过另一组隐藏层处理后,潜在表示将转换为一个输出向量,其中每个条目可以表示个人与特定位置之间的链接强度。有时,混合专家(MoE) 的思想可以应用于此范例中,根据输入激活大型模型中的不同模块(或专家),从而以更少的资源获得更准确的结果。
图10所展示的不仅仅是粗粒度知识融合范例。如果一个模型首先将多模态数据转化为潜在表征,然后在类似深度神经网络的模型中融合它们,那么这个模型就属于粗粒度知识融合范畴。一旦专业人员经历了图3中所示的领域层和链接层,即了解“融合什么”和“为什么可以融合”,他们就可以选择一种知识融合范例,然后设计特定的模型结构(可能与图10中所示的模型结构非常不同),以解决他们自己的问题。
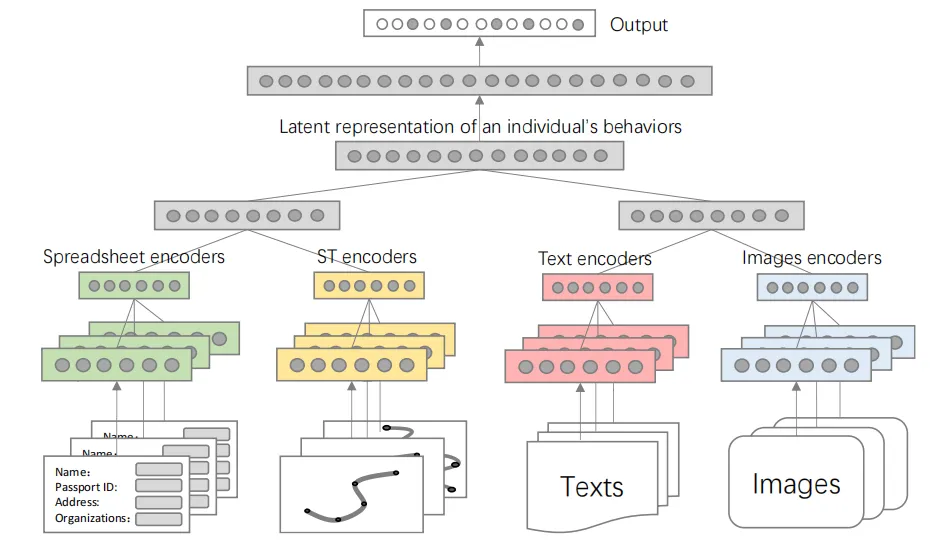
图10. 粗略知识融合范式示例
2.4 数据转换(Data层)
2.4.1数据转换的动机与关键因素
不同模态的数据具有不同的结构、尺度、分辨率和分布,这使得它们无法被人工智能模型直接处理。具有不同结构的数据需要不同的编码算法,以便在将它们发送到AI模型之前,将其转换为一致的表示形式。尺度差异显著的数据会导致脆弱的训练过程。不同分辨率的数据需要不同结构的AI模型,例如输入的大小和隐藏层的数量。在类别标签或空间和时空上具有不同分布的数据会误导AI模型的推理。
因此,在将选定的多模态数据发送到设计的AI模型之前,我们需要将它们转换为一致的表示形式,以应对由不同结构、尺度、分辨率和分布所带来的挑战。
数据转换过程取决于两个主要因素。一是数据模态的内在属性,它表示要处理的数据集的性质,而与应用无关。另一种是多模态数据之间的链接,这取决于问题、领域和知识对齐的方法,这可以被认为是数据对应用的适应。也就是说,相同模态的数据可以通过不同的转换算法在不同的应用场景中生成不同的表示。也就是说,相同模态的数据可以有不同的。
2.4.2数据转换的架构
如图11所示,数据变换的体系结构由三个部分组成:数据预处理、精确变换和粗变换,生成三种数据变换方法 (①, ② 和③)。数据处理是一个基础操作,解决了不同数据分布、规模和分辨率带来的挑战。后两个变换模块主要解决了数据异构性和数据稀疏性带来的问题。结合数据预处理,两个变换模块分别制定了精确变换方法(表示为①)和粗略变换方法(表示为②)。有时,精确变换后可以进行粗略变换过程,生成混合方法如③所示。 数据转换方法的选择取决于应用程序的特性和数据模式的性质。
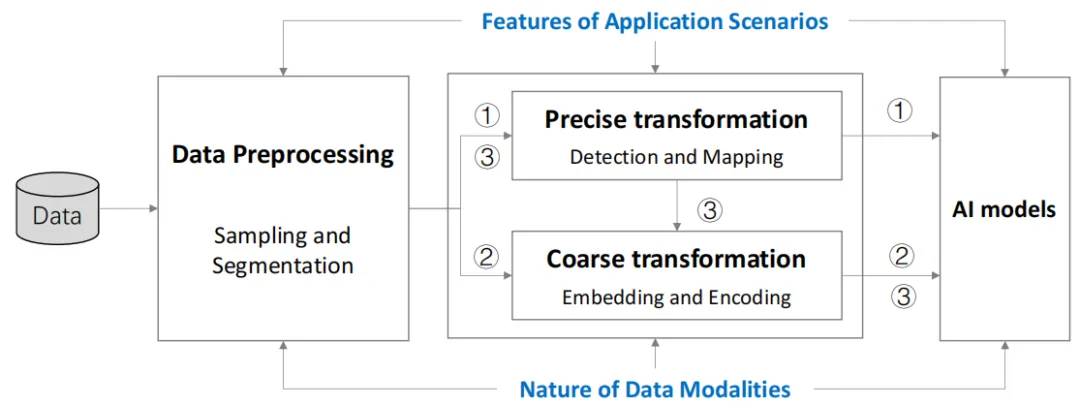
图11. 数据转换框架
数据预处理。该模块由数据采样和分割方法组成。1) 数据抽样方法从原始数据集中选择必要数量的实例,以实现类标签的均匀分布,从而应对不同数据分布带来的挑战。它通过跳过冗余数据来缩小数据集的大小,从而减少计算工作量。这些抽样方法还将不同分辨率的实例转换为可比较的实例,以实现一致的计算过程,从而解决由不同数据分辨率引起的问题。例如,将不同分辨率的照片抽样到一致的像素级别,或者将不同记录频率的轨迹向上或向下抽样到相同的时间粒度。2) 分割方法将数据划分为不同的片段,使得每个片段具有相同的尺度级别,或者可以识别出感兴趣的片段。如图 12 A) 所示,当处理非常长的文档时,我们通常将其划分为长度相似的若干部分。轨迹可以通过空间距离d或时间跨度t分割成均匀的片段,如图 12 B) 所示。之后,可以一起处理具有不同空间和时间尺度的轨迹。如图 12 C) 所示,为了更好地分析重要的对象,例如人或建筑物,我们需要使用图像分割方法从图像背景中分割出感兴趣的区域。

图12. 数据分割示例
精确数据转换。该模块由检测和映射方法组成,这些方法在数据模态上各不相同。1) 检测方法从多模态数据中提取关键要素,然后使用这些要素来表示原始数据。我们可以使用空间聚类算法、分层聚类算法,也可以基于字典使用实体提取算法从给定的文档中检测实体名称。2) 映射方法将数据投影到一个共享框架上,或将它们与一个共同的基准进行匹配,从而生成一个简化且一致的数据表示。
粗略数据转换。粗略数据转换并非检测精确知识并进行精确匹配,而是采用嵌入算法或编码器将数据转换为中间表示,其中隐含地携带压缩知识。1) 表征学习技术已被广泛研究,用于将非结构化数据压缩成密集且长度固定的表示,并进一步用于下游应用。例如,已经提出了不同类型的方法,包括主题模型、词嵌入算法和自编码器等,用于估计文本的连续表征。2) 相当多的研究工作采用上述嵌入算法或编码器来学习时空数据的表示。尽管这些模型在一定程度上降低了下游应用的计算复杂度,但引入的独特空间和时间属性并没有在潜在表示中得到很好的保留。应该为时空数据设计专门的嵌入算法或编码器,以保留独特的空间和时间属性。3) 关于结构化数据,已经提出了大量的网络嵌入算法,能用低维且密集的向量来表示网络中的各节点,这些向量保留了网络的拓扑和节点的内容。网络可以表示朋友之间的社会关系、作者之间的信息传递以及分子之间的生物相互作用。然而,目前缺乏在“在线表单”里的嵌入字段(如姓名、年龄、议程、地址)的表征学习方法。这些字段是实体及其属性的底层图结构,而不是单词序列。
三.总结
论文系统提出跨域多模态知识融合框架,旨在解决物理世界复杂问题。郑宇教授指出现有研究多聚焦单域融合,而现实任务常需跨域数据。论文通过四层结构(Domains、Links、Models、Data)回答“融合什么、为何能融合、如何融合”,提出多视角、相似性、依赖性、共性四大知识对齐原则,并总结精细与粗糙两种融合范式。方法在空气质量预测、城市规划、交通管理等场景展现价值,同时讨论挑战与未来方向。
 |

图文|周钦钦
校稿|李瑞远
编辑|刘苧锐
审核|李瑞远
审核|杨广超
0 条评论