Spark on Microsoft Azure(1)-Create a Spark in HDInsight
Spark是一个开源、分布式、基于内存的实时处理平台。与Hadoop相比,由于Spark是基于内存的,减少了磁盘IO,因此具有更好的性能。这篇文章主要讲述Microsoft Azure HDInsight上的Spark平台。
1、首先得拥有一个Azure的订阅号。截止到2016年8月,Spark只存在于Azure Global版本中,Azure China并未上线。
2、截止到2016年8月,只在Azure新portal上能够创建HDInsight,老的portal已经显示为禁用状态。
3、在Azure新门户中,点击新建-》数据+分析-》HDInsight,输入集群名称,并选择订阅号。集群名称不可以与已有的集群冲突。你可能拥有多个订阅号,选择其中的一个,所产生的费用将从选定的订阅号中扣除。

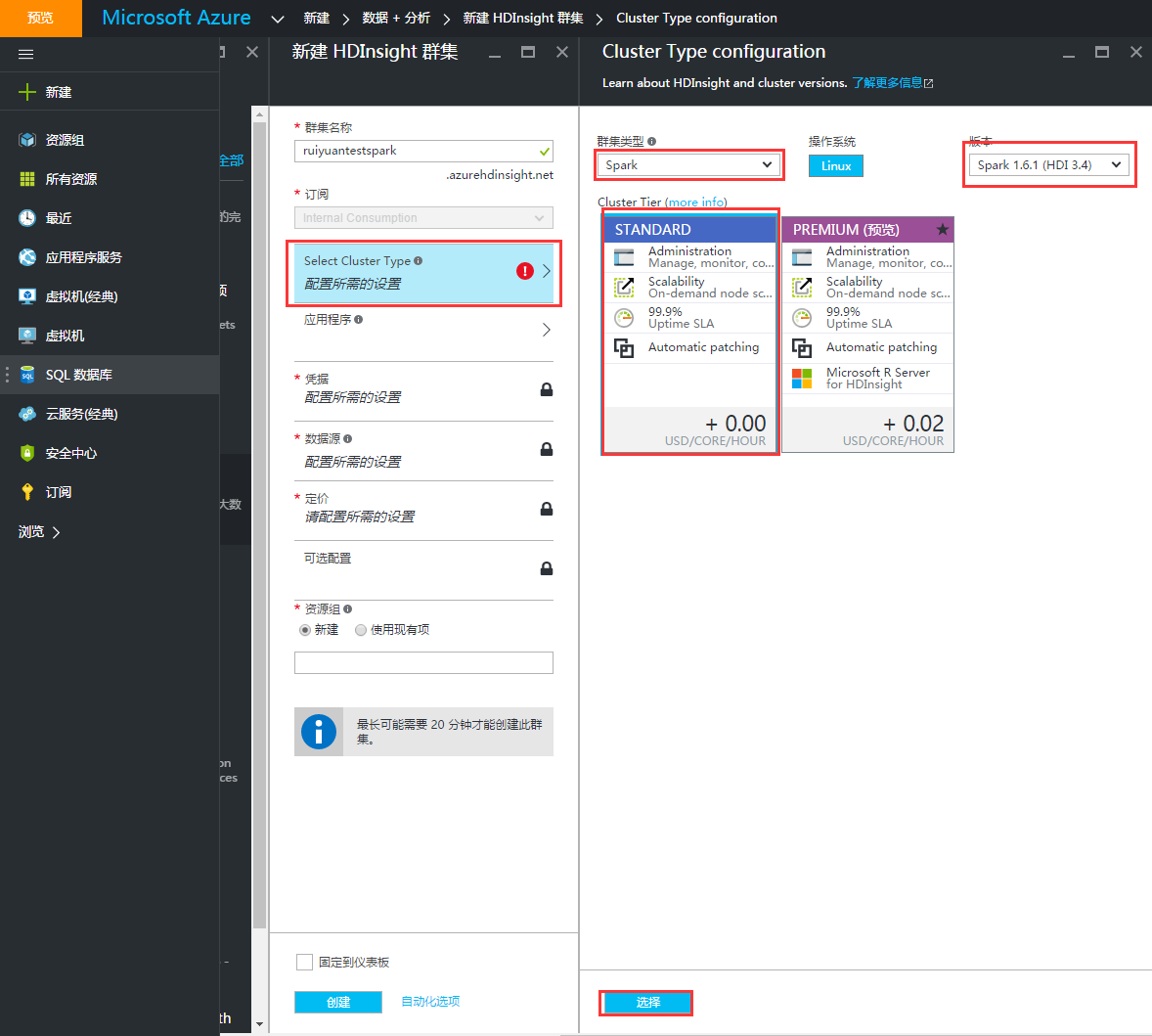
4、选择集群类型。HDInsight中包含Hadoop、HBase、Spark、Storm等。这里,我们选择Spark。目前HDInsight中的Spark只支持Linux系统。选择Spark版本及计费节点。
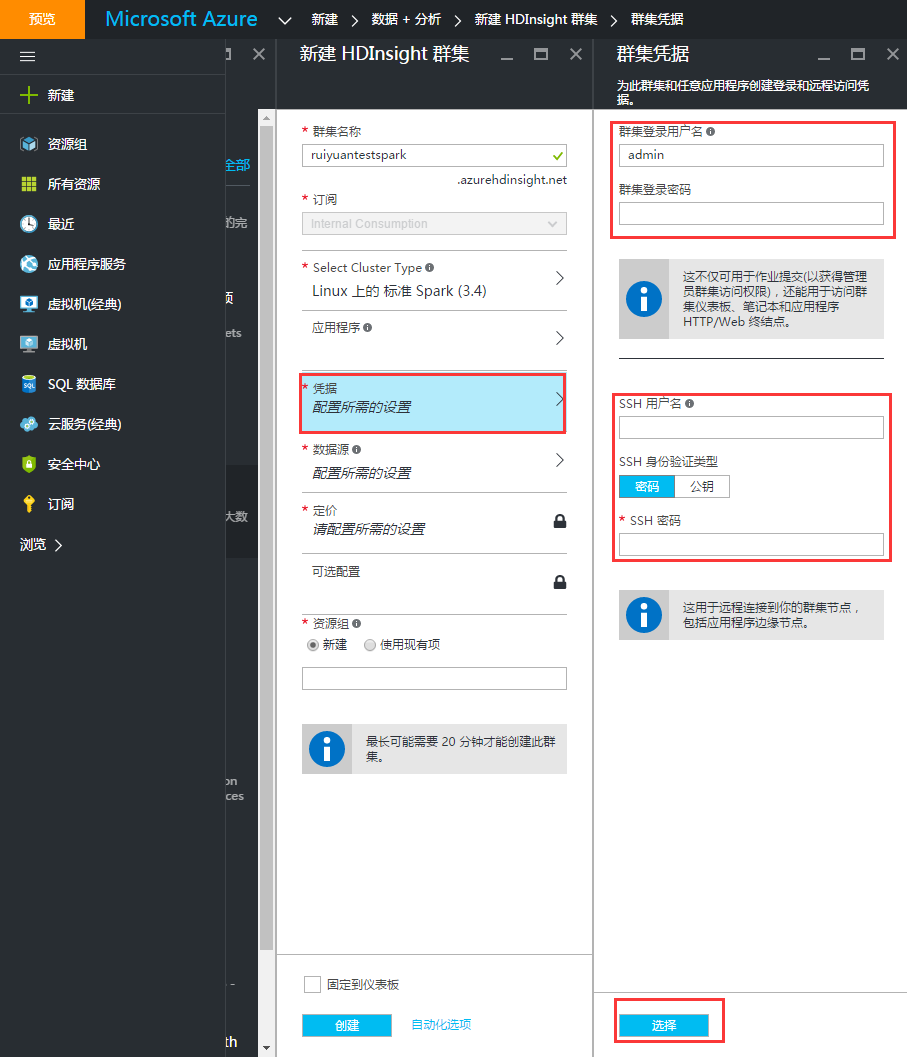
5、输入登录集群凭据。包括集群登录用户名、登录密码以及SSH用户名和密码。为简单起见,这里我们选择SSH身份验证为密码验证。用户名密码得牢记,后续管理集群是需要用到。
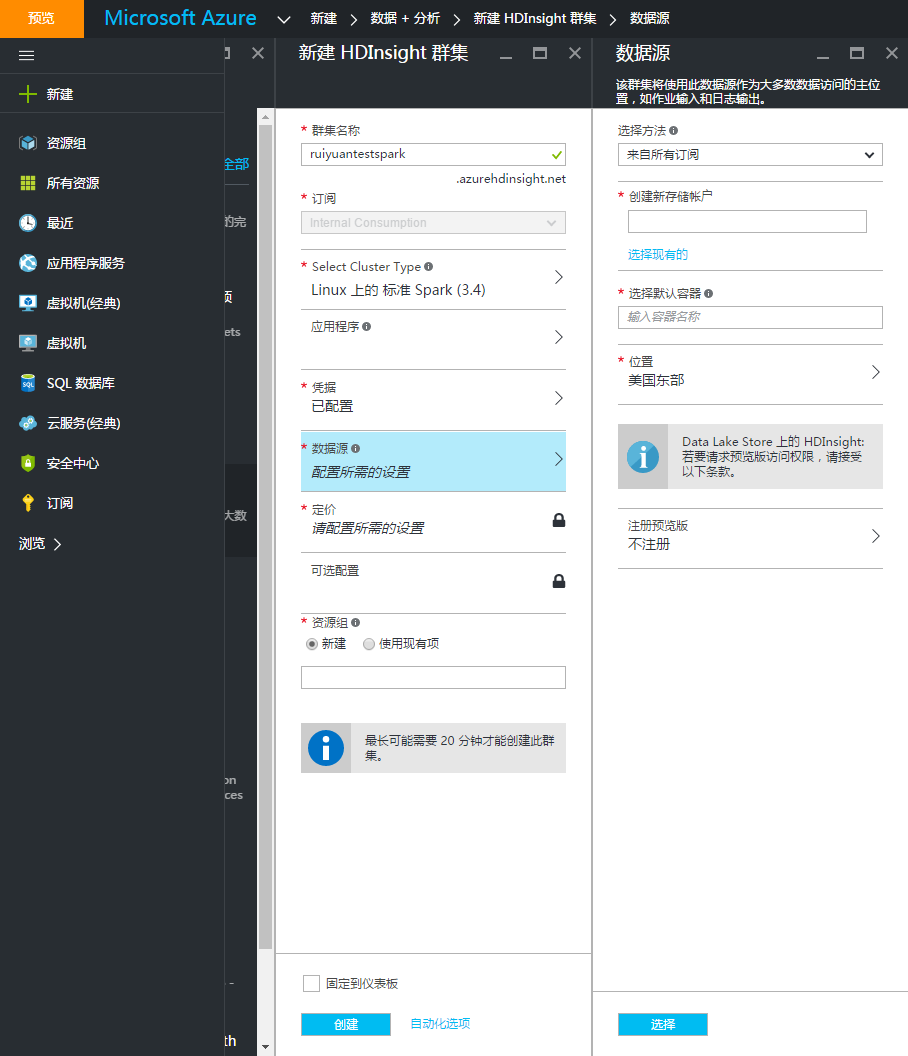
6、选择数据源。Spark的数据源默认是在Azure的Storage里面,目前预览版可以切换至Data Lake Store。这里我们创建新的存储账户,并输入默认的容器名称,选择位置在东亚。
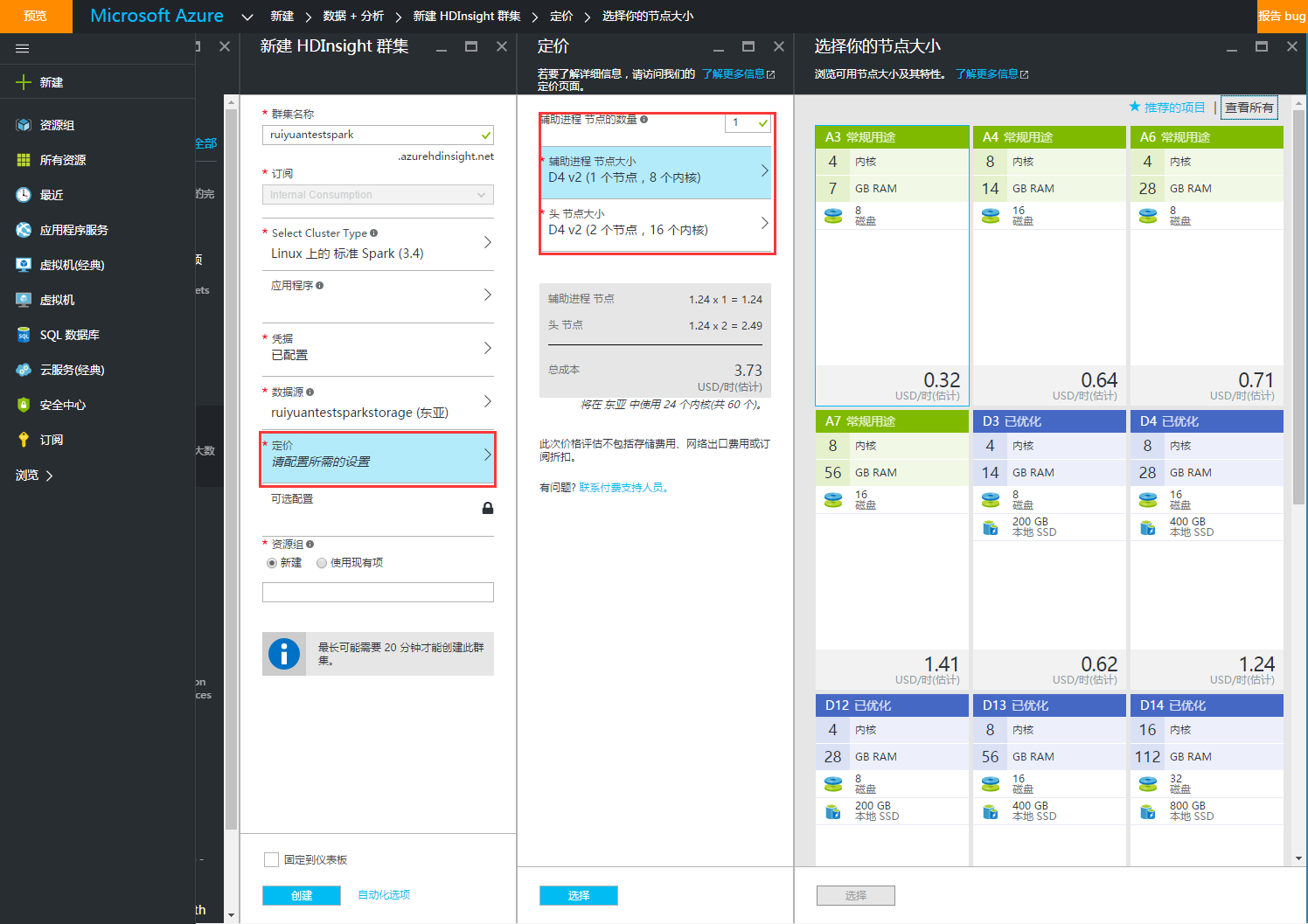
7、选择定价层。由于我们目前只是测试,因此我选择1个辅助进程节点,并使用尽可能低的配置。辅助进程和头结点的节点大小选择A3。即使这样,每个小时仍需0.96美元(窃以为还是非常贵的)
8、资源组为了方便azure资源的管理,我们这里输入ruiyuantest。最后点击创建按钮。创建过程可能比较长,笔者花费大约15分钟。
0 条评论